My Network Packets
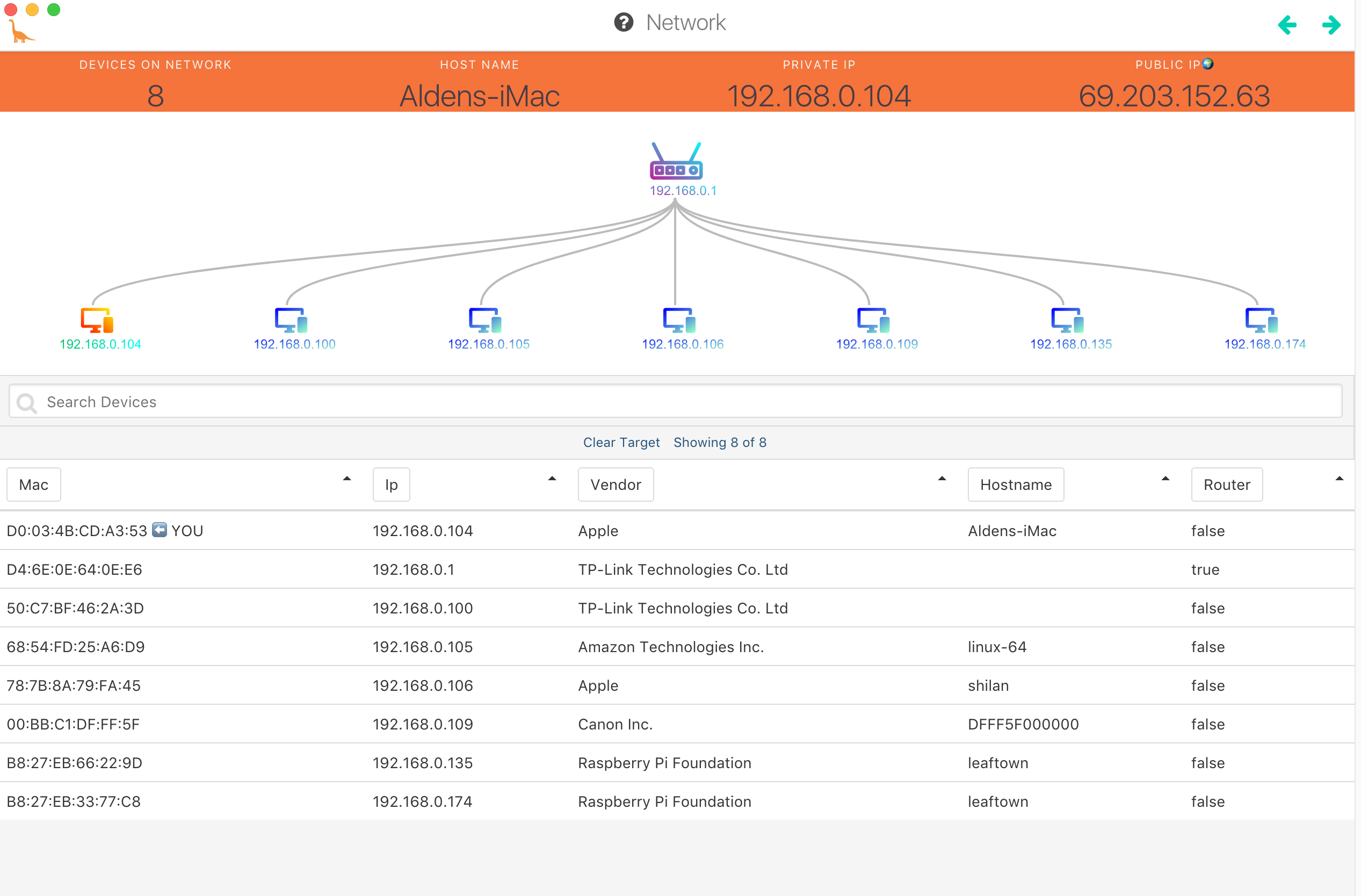
My network map was more or less what I expected to see. Here’s the map from Herbivore.
 Note that my public IP’s threat level is low.
Note that my public IP’s threat level is low.
The TP-Link at 192.168.0.1 is, naturally, my router. The TP-Link at .100 is actually my wifi-enabled plug from the same manufacturer. The Amazon Technologies device is an Echo (running 64 bit Linux? I thought they ran ‘Amazon Fire’ EDIT: looks like Fire OS has a Linux kernel), The Canon is a printer, the Pis are actually a single Pi connected via both wifi and ethernet. It’s called ‘leaftown’ because it’s what I use to talk with my plants. Whenever I try to sniff either the Echo or the TP-Link plug with Herbivore the devices go offline and become unable to communicate. When this happens with the Echo it sends 7 “keep-alive” packets in rapid succession to 52.216.161.179, which I found belongs to an Amazon S3 instance. Curious. Maybe a security measure to keep these devices from ending up on Shodan. All of those packets are all header no content with headers like this:
GET /kindle-wifi/wifistub-echo.html HTTP/1.1
User-Agent: Java
Host: spectrum.s3.amazonaws.com
Connection: Keep-Alive
Accept-Encoding: gzip
Already so many questions. This is clearly a rabbit hole. Since http://52.216.161.179/kindle-wifi/wifistub-echo.html gives me an access denied XML in my browser, more on the wifistub-echo.html will have to wait. Skipping down to the User-Agent: Java, it seems like the User-Agent line in HTTP packets usually specifies the browser of origin. Since for the Echo’s it is labeled Java, it’s probably creating the packet with a Java program. The Host: spectrum.s3.amazonaws.com is the same IP address the packet was being sent to, but the spectrum part is a bit interesting. Is this a specific Echo S3 instance for Spectrum customers?
With Connection: Keep-Alive, I learned a bit about keep alive statements over HTTP from Wikipedia. Actually, moving back a bit, I learned that packets have two parts: header and payload. Next line down,
Accept-Encoding: gzip, identifies something interesting: packet payloads are frequently compressed.
The sheer magnitude of packets zipping around my network is overwhelming. I left Wireshark running for 24 hours, thinking that a day would be a manageable amount of data to work with, and ended up creating a nearly 4.5GB log file (other than its size my attention was also drawn to its filetype, pcapng, which I had never seen before - I learned a bit more about PcapNg on the Wireshark wiki). Maybe that shouldn’t be so surprising, after all we use the internet at home a fair amount, watch videos, stream music, etc. All of that is packets.
This amount of data made Wireshark slow to a crawl whenever I tried to use it. So I decided to leave the day of packets on the table for now and focus on an easier unit of analysis, 45 minutes. Looking protocol by protocol I found I had
- ARP
- DB-LSP-DISC
- DHCP
- DHCPv6
- DNS
- GQUIC
- HTTP
- HTTP/XML
- ICMP
- ICMPv6
- IGMPv2
- MDNS
- NBNS
- NTP
- OCSP
- SSDP
- STP
- TCP
- TLSv1.2
- TLSv1.3
- UDP
The bulk are TCP packets. I think the ARPs were mostly from opening Herbivore actually. Interesting to see it in action.
 The complexity is getting to me. I’m learning that MDNS is DNS for local networks. Makes sense why my Pi might be asking my desktop for ID.
The complexity is getting to me. I’m learning that MDNS is DNS for local networks. Makes sense why my Pi might be asking my desktop for ID.
 DB-LSP-DISC is for Dropbox, apparently.
DB-LSP-DISC is for Dropbox, apparently.
Now why didn’t I convert the PcapNg’s into something more useable and import them into Python where I could create cool visualizations and stuff? Well I found a tool that would let me import the logs directly into a Python project, but it only ran on Python2. “No problem!” I innocently thought, “I’ll just create a Python2.7 virtual environment”. I run virtualenv. An error. What could be wrong? I check and recheck. Aha. It’s my paths, when I installed Anaconda recently it created itself a folder called anaconda3, which I changed to just anaconda so that I could be consistent between my laptop and desktop. It looks like all of Anaconda’s internal files still reference acaconda3. Hm but if I change it back to anaconda3 it will break my workflow. Fast forward about an hour and I’m shaving a yak, another hour and I’m running the following command on my home directory.
grep -rli 'anaconda3/bin/python' . | xargs -I@ sed -i '' -e 's/anaconda3/anaconda/g' @
Voila now I can run virtualenv. Why did I want to do that again?
Extra note:
I use this Scala code to check my public IP, if you ever need it outside of using Herbivore.
val addr = scala.io.Source.fromURL("https://api.ipify.org").mkString
println(s"My public IP address is: $addr")